 前言:ATE测试在集成电路的生产流程中发挥着至关重要的作用。测试一个晶圆(Wafer)时,会产生的大量数据需进行深入分析以评估电路的性能。在这之中,shmoo图的绘制是其中一种广为使用的分析方法。 对于非专业人士,Shmoo图可能是一个陌生的术语。简而言之,它是一个展示两个变量间关系的二维图表。但Shmoo图远不止于此——在半导体测试中,它是一个高度信息化的可视化工具。通过Shmoo图,工程师可以直观地解析大量的数据,为质量控制、可靠性评估和决策提供关键信息。 烦恼如浮云遮月,写写脚本净心静气。 Python脚本目标: 本脚本旨在将ATE测试数据转化为Excel中的Shmoo图,并对多个芯片数据进行叠加显示: · 颜色化显示:每个芯片的测试数据(由0和1组成的二维数组,0代表Fail,1代表Pass)将被转化为颜色 。 · 统计学叠加:叠加多批次、多芯片的相同测试项的shmoo图,能够快速揭示某参数组合下的芯片特性。体现在excel的最左侧并进行了窗口冻结处理。 开门见山吧,测试结果如下:  代码如下: # -*- coding: utf-8 -*- """ Created on Fri Oct 20 20:27:33 2023 @author: ryan """ import openpyxl from openpyxl.styles import PatternFill, Border, Side import numpy as np class ArrayDataset: """ArrayDataset 类:表示单个数据集并存储其相关信息""" def __init__(self, source_name, x_axis_name, y_axis_name, x_values, y_values): """构造函数初始化数据集的元信息和x,y轴的值""" self.source_name = source_name self.x_axis_name = x_axis_name self.y_axis_name = y_axis_name self.x_values = x_values self.y_values = y_values self.arrays = [] def add_array(self, array_name, array_data): """向数据集添加一个数组""" self.arrays.append({"name": array_name, "data": array_data}) class ExcelGeneratorWithSpacing: """ExcelGeneratorWithSpacing 类:根据提供的数据集生成Excel文件""" # 设定颜色和边框样式 RED_FILL = PatternFill(start_color="FF0000", end_color="FF0000", fill_type="solid") GREEN_FILL = PatternFill(start_color="00FF00", end_color="00FF00", fill_type="solid") BORDER = Border(left=Side(border_style="thin", color="000000"), right=Side(border_style="thin", color="000000"), top=Side(border_style="thin", color="000000"), bottom=Side(border_style="thin", color="000000")) def __init__(self, datasets): """构造函数初始化工作簿和工作表对象,并设置数据集""" self.datasets = datasets self.wb = openpyxl.Workbook() self.ws = self.wb.active def add_axes_and_labels(self, start_row, start_col, dataset): """在Excel中添加轴标签和数据集的x和y轴值""" # 添加x轴值 for j, x_val in enumerate(dataset.x_values): cell = self.ws.cell(row=start_row + len(dataset.y_values) + 2, column=start_col + j) cell.value = x_val # 添加y轴值,注意y轴值是反转的 for i, y_val in enumerate(reversed(dataset.y_values)): cell = self.ws.cell(row=start_row + i + 2, column=start_col - 1) cell.value = y_val # 添加x和y轴名字 self.ws.cell(row=start_row + len(dataset.y_values) + 3, column=start_col + len(dataset.x_values) // 2).value = dataset.x_axis_name self.ws.cell(row=start_row + len(dataset.y_values) // 2 + 1, column=start_col - 2).value = dataset.y_axis_name def generate_excel(self, file_name): """根据数据集生成Excel文件""" start_row = 1 # 初始化开始行 for dataset in self.datasets: start_col = 5 # 初始化开始列 # 首先,计算2D数组的和 summed_array = np.sum([array_info["data"] for array_info in dataset.arrays], axis=0) # 创建温暖的渐变颜色,基于零的数量 max_value = int(summed_array.max()) warm_gradient_colors = { i: f"{hex(255)[2:].zfill(2)}{hex(255 - int(i/max_value*255))[2:].zfill(2)}00" for i in range(1, max_value) } # 为summed_array添加颜色和值 for i, row in enumerate(summed_array): for j, value in enumerate(row): cell = self.ws.cell(row=start_row + i + 2, column=start_col + j) if value == 0: cell.fill = ExcelGeneratorWithSpacing.RED_FILL elif value == len(dataset.arrays): cell.fill = ExcelGeneratorWithSpacing.GREEN_FILL else: cell.value = summed_array[i,j] cell.fill = PatternFill(start_color=warm_gradient_colors[cell.value], end_color=warm_gradient_colors[cell.value], fill_type="solid") cell.border = ExcelGeneratorWithSpacing.BORDER # 添加轴和标签 self.add_axes_and_labels(start_row, start_col, dataset) # 标注数据源名称 source_name_cell = self.ws.cell(row=start_row + 2, column=1) source_name_cell.value = dataset.source_name # 然后,添加单个数组 start_col += len(summed_array[0]) + 5 + 3 start_col_sum = start_col for array_info in dataset.arrays: array_data = array_info["data"] for i, row in enumerate(array_data): for j, value in enumerate(row): cell = self.ws.cell(row=start_row + i + 2, column=start_col + j) if value == 0: cell.fill = ExcelGeneratorWithSpacing.RED_FILL else: cell.fill = ExcelGeneratorWithSpacing.GREEN_FILL cell.border = ExcelGeneratorWithSpacing.BORDER # 添加轴和标签 self.add_axes_and_labels(start_row, start_col, dataset) # 标注die名称 die_name_cell = self.ws.cell(row=start_row + 1, column=start_col) die_name_cell.value = array_info['name'] start_col += len(array_data[0]) + 3 # 调整下一个数据集的行开始位置 start_row += len(dataset.y_values) + 7 # 7是为了考虑轴、标签和3行的间距 # 调整列宽和行高以达到统一的单元格大小 for col in self.ws.columns: adjusted_width = 4 # 设置固定宽度以达到统一的单元格大小 self.ws.column_dimensions[col[0].column_letter].width = adjusted_width # 第一列固定。 self.ws.column_dimensions['A'].width = 25 for row in self.ws.rows: for cell in row: cell.alignment = openpyxl.styles.Alignment(horizontal='center', vertical='center') # 水平和垂直居中对齐 adjusted_height = 20 # 设置固定高度以达到统一的单元格大小 self.ws.row_dimensions[row[0].row].height = adjusted_height # 最后保存文件 self.wb.save(file_name) if __name__ == "__main__": dataset1 = ArrayDataset(source_name="data_source_1", x_axis_name="x1", y_axis_name="y1", x_values=list(range(1, 11)), y_values=list(range(1, 11))) for i in range(5): data = np.random.randint(0, 2, size=(10, 10)) dataset1.add_array(f"array_{i}", data) dataset2 = ArrayDataset(source_name="data_source_2", x_axis_name="x2", y_axis_name="y2", x_values=list(range(1, 11)), y_values=list(range(1, 11))) for i in range(3): data = np.random.randint(0, 2, size=(10, 10)) dataset2.add_array(f"array_{i}", data) gen = ExcelGeneratorWithSpacing([dataset1, dataset2]) gen.generate_excel("sample_output.xlsx") if __name__ == "__main__": # 定义数据集使用的x和y值 # 使用np.linspace在指定的两个限制值之间生成均匀分布的值。 x_values = np.linspace(0.8, 1.2, 11).tolist() # 定义x轴的值 y_values = np.linspace(0.5, 2, 11).tolist() # 定义y轴的值 # 创建和填充数据集的函数 # 此函数自动化创建一个填充有随机数组的数据集的过程。 def generate_dataset(source_name, seed_value): # 设置随机数生成的种子,确保结果可复现。 np.random.seed(seed_value) # 使用指定的名称、x和y值初始化一个新的数据集。 dataset = ArrayDataset(source_name, "Vcoef", "Tcoef", x_values, y_values) # 定义生成数组过程中使用的常量。 num_arrays = 10 rows = 11 cols = 11 # 循环生成多个数组并将其添加到数据集中。 for m in range(20): for _ in range(num_arrays): # 从填充有1的上三角矩阵开始。 array = np.triu(np.ones((rows, cols)), k=0) # 根据指定的条件修改数组中的值。 for i in range(rows): for j in range(cols): if i > j: array[i, j] = 0 elif i < (j-1): array[i, j] = 1 else: # 随机选择0或1。 array[i, j] = np.random.choice([0, 1]) # 将生成的数组添加到数据集。 dataset.add_array(f"Die_{m+1}", array) return dataset # 使用前面定义的函数生成数据集。 # 每个数据集都有一个唯一的源名称和种子值。 dataset_bscan_01 = generate_dataset("FC_MBIST_XX_01", 12) dataset_bscan_02 = generate_dataset("FC_MBIST_XX_02", 42) # 使用生成的数据集初始化Excel生成器。 # 数据集以列表的形式传递给生成器。 generator = ExcelGeneratorWithSpacing([dataset_bscan_01, dataset_bscan_02, dataset_bscan_02]) # 定义输出Excel文件的名称。 output_file_name = "to_save_your_file.xlsx" # 调用函数生成Excel文件。 generator.generate_excel(output_file_name) 如何使用 参考上述代码 if __name__ == "__main__":下的测试用例。构造了一系列假的11✖11的二维数组对应不同芯片的测试结果,元素的值为0/1. 数据输入:工具的效率始于有效的输入。因此,定义了ArrayDataset类,为你的测试数据提供了统一和直观的接口。这有助于简化数据的集成过程。 为何使用数据类?由于不同公司的ATE输出数据格式可能有所不同,定义此类可以确保我们的工具适用于多种格式。然而,用户可能还需简单处理ATE数据,以确保其符合我定义的输入格式。 初始化数据类: 创建ArrayDataset对象时,你需要提供以下信息: source_name(测试项名称) x_axis_name(shmoo图的x轴名称或描述) y_axis_name(shmoo图的y轴名称或描述) x_values(x轴坐标刻度) y_values(y轴坐标范围) 示例: x_values = np.linspace(0.8, 1.2, 11).tolist() y_values = np.linspace(0.5, 2, 11).tolist() dataset = ArrayDataset("FC_MBIST_XX_01", "Vcoef", "Tcoef", x_values, y_values) 一旦一个ArrayDataset 被初始化,你可以开始添加多个二维数组到这个数据集中。这些数组代表了同一个测试项不同芯片的测试结果。使用 add_array 方法可以轻松地完成这个任务。 示例: dataset.add_array("Die_1", array_data) 假如你有三个测试项,则初始化三个dataset,传入脚本即可: # 使用生成的数据集初始化Excel生成器。 # 数据集以列表的形式传递给生成器。 generator = ExcelGeneratorWithSpacing([dataset_bscan_01, dataset_bscan_02, dataset_bscan_03]) 你可能会问,为什么我不能直接传递我的二维数组呢?这里的关键在于组织。考虑到一个晶圆上可能有多达数百或数千的芯片,ArrayDataset 为我们提供了一个集中和组织这些数据的方法。更重要的是,它为你提供了一个简单的接口,你只需关心你的测试数据,不必担心如何在工具中处理它们。 下面继续展示不同尺寸的图示作为结束语: o 第1列为测试项名称 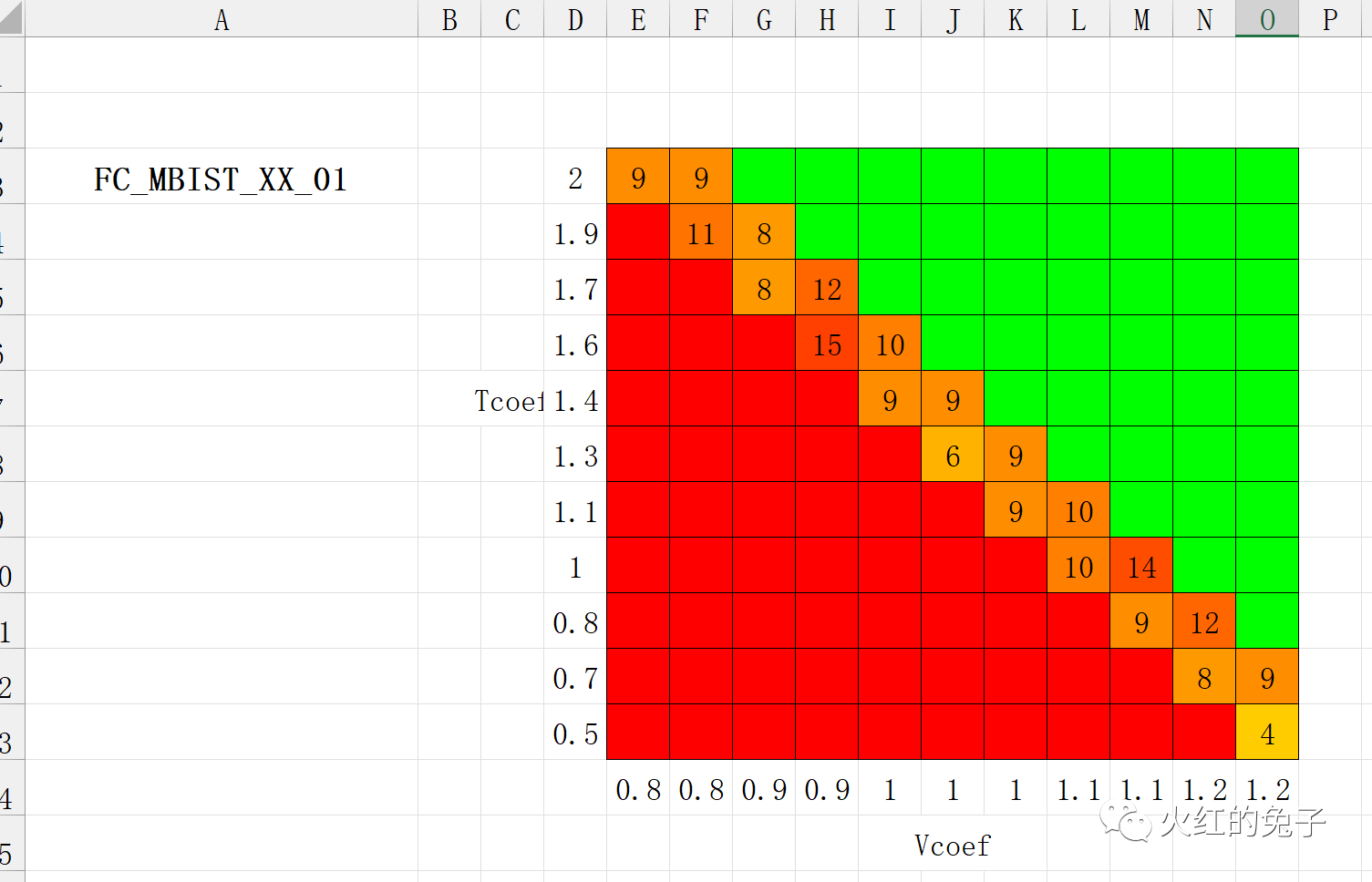 o 统计叠加的shmoo图之前做了窗口冻结,这样不同Die的图形可以与叠加图时刻做对比 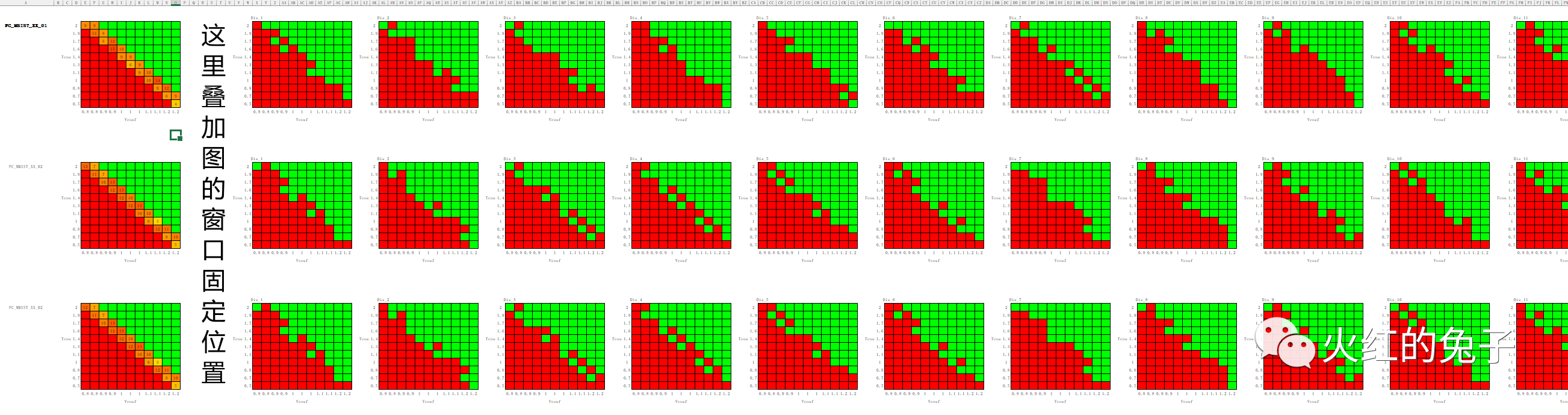 |



